この記事はFirebase Advent Calendar 2018の12日目の記事です。 以前にCloud Firestore rules tipsを書いてから時間が経過したことと、その記事を書いてから僕自信もより理解を深めることができたので、改訂版としてこの記事を書きます。
はじめに
基礎的な部分やリファレンスについては公式を参照するのが一番手っ取り早いです。
- Cloud Firestore セキュリティ ルールを設定する
- Cloud Firestore セキュリティ ルールをカスタマイズする
- Cloud Firestore Security Rules Reference
Basic
読み書きのルールは基本的に許可制
Firestoreのread/writeのルールはとてもシンプルで、何も指定がなければドキュメントに対するread/writeの操作は 拒否 されます。
以下の例では、/cities コレクション内のドキュメントに対するread/writeに関しては許可されますが、/buildings コレクション内のドキュメントに対するread/writeは拒否されます。
service cloud.firestore {
match /databases/{database}/documents {
match /cities/{cityID} {
allow read, write: if true;
}
}
}
また、明示的に allow xxx: if false を書く必要はありません。
ちなみに、
service cloud.firestore {
match /databases/{database}/documents {
}
}
この部分まではおまじないと思ってもらえれば大丈夫です。
/databases/{database}/documents で、FirestoreのDBの / (ルート) を指し示していると理解して大丈夫です。
match文はネストして書ける
基本的にはmatch文は直列で長く書くよりはネストさせて書いたほうが絶対に良いです。理由として、
- コレクションの階層が把握しやすい
- 各階層のドキュメントに付与するワイルドカード変数の使用、関数定義のときに都合が良い
が挙げられます。
service cloud.firestore {
match /databases/{database}/documents/users/{userID} {
// ...
}
match /databases/{database}/documents/blogs/{blogID} {
// ...
}
match /databases/{database}/documents/blogs/{blogID}/images/{imageID} {
// ...
}
}
🤔
service cloud.firestore {
match /databases/{database}/documents {
match /users/{userID} {
// ...
}
match /blogs/{blogID} {
// ...
match /images/{imageID} {
// ...
}
}
}
}
🎉
基本的にはこのようにネストさせていく書き方をしましょう。
また、特定のドキュメントに対するmatch文は1回までしか定義できません。2つ以上定義があると構文エラーになります。以下はだめな例になります。
service cloud.firestore {
match /databases/{database}/documents {
match /users/{userID} {
// ...
}
// ...
match /users/{userID} { // error!
// ...
}
}
}
allow式で使用するアクセス権
allow式で使用するアクセス権にはreadとwriteの2つがありますが、そこから更に細分化されいます。
- read
- get
- list
- write
- create
- update
- delete
個人的には純粋にread/writeで使うよりは、目的別でget/list/create/update/deleteを使い分けることが多いです。
例えば単体取得は許可するが、複数取得は一切許可したくない時はreadではなくgetで式を書く。
作成と更新は制御したいが、削除は拒否したい場合はwriteではなくcreate/updateを使う。
という具合に、細かく最小限でルールを構成するようにします。
allow read: if request.auth != null;
allow create, update: if request.auth != null && request.resource.data.userID == request.auth.uid;
allow delete: if request.auth != null && resource.data.userID == request.auth.uid;
ワイルドカード
ワイルドカードとはmatch /users/{userID} の {userID}の部分の事です。
変数名は任意のもので良いです。個人的にはxxxIDと付けることが多いです。ちょうど各documentのIDにあたるので。
そのワイルドカードは変数として使うことができ、ルールが実際に適応される時に、参照されるdocumentのIDが内部的に展開され用いられるようになります。
以下は簡単な例です。
service cloud.firestore {
match /databases/{database}/documents {
match /users/{userID} {
allow read: if request.auth != null;
allow write: if request.auth.uid == userID;
}
}
}
ネストしている場合でも、親ドキュメントのIDを参照することができます。
service cloud.firestore {
match /databases/{database}/documents {
match /users/{userID} {
allow read: if request.auth != null;
allow write: if request.auth.uid == userID;
match /posts/{postID} {
allow read, write: if request.auth.uid == userID;
}
}
}
}
カスケード
Firestoreのルールは、ルールの条件を書いたそのドキュメントの階層にのみ適応され、下層にあたるサブコレクションには(自動的には)適応されません。
もし下層のサブコレクションにも同様のルールを適応したい(カスケードしたい)場合には、match文のpathのワイルドカード変数のあとに =** を付与してあげます。
service cloud.firestore {
match /databases/{database}/documents {
match /users/{userID=**} {
allow read: if request.auth != nil;
}
}
}
これで、/users/{userID}/images/{imageID},/users/userID}/posts/{postID}といった下層のサブコレクション全てに、/users/{userID}と同じルールが適応されます。
ちなみにカスケードを適応した場合、その中にmatch文をネストして書くことができなくなるので注意です。
以下は間違ったルールの書き方になります。
service cloud.firestore {
match /databases/{database}/documents {
match /users/{userID=**} {
allow read: if request.auth != nil;
match /item/{itemID} {
// ...
}
}
}
}
「Glob(**) resource rules should not have child resource rules.」 というエラーが発生します。
特定のドキュメントとその下層のサブコレクションとでルールを分ける allChildren=**
上述のカスケードでは、そのドキュメントと、そのドキュメント以下の全てのサブコレクションでルールを分けたい場合に困ることになります。
そういう時は以下のようにallChildren=**を用いると、ルールを分けることができます
service cloud.firestore {
match /databases/{database}/documents {
match /articles/{articleID} {
allow read: if wwww;
allow write: if xxxx;
match {allChildren=**} {
allow read: if yyyy;
allow write: if zzzz;
}
}
}
}
これで、articleドキュメントに対するルールと、article以下の全てのサブコレクションに対する一律のルールとで分離することができます。
ルールは狭く深く、不用意に浅いところで許可しない
Firestoreで重要なルールとして、許可制であることと、もう一つはルールはなるべく狭く深いところで必要なときに許可してあげることです。
あるドキュメントに対して、複数のルールが別々に定義されていた場合は、それらのルールが and ではなく、 or で評価される点に注意してください。
例えば、 /users/{userID}に対して
allow write: if request.auth != null && request.auth.uid == userIDallow write: if true
という複数条件が与えられて(しまっていた)場合、前者で防げていたとしても、後者が成立してしまい、結果として書き込みが許可されてしまうので、ルールの意味を成さなくなります。
よく嵌まる例
各種モデルに一律でrequest.auth != nullであることをread, writeに付与しようと思って次のように書きます。
service cloud.firestore {
match /databases/{database}/documents {
function isAuthenticated() {
return request.auth != null;
}
function isUserAuthenticated(userID) {
return request.auth.uid == userID;
}
// `/` 以下に isAuthenticated() を適応
match /{allChildren=**} {
allow read, write: if isAuthenticated();
}
match /users/{userID} {
// userIDとauth.uidが一致するか且つ、何かしらの条件に一致する
allow read, create, update: if isUserAuthenticated(userID) && someCondition();
}
}
}
実はこれは間違いで、これも/users/{userID}に対して、認証さえ通っているユーザーであれば自由に書き込みができてしまう状態になってしまいます。
正しくは以下のように面倒でも狭く深くするのが正解です。
service cloud.firestore {
match /databases/{database}/documents {
function isAuthenticated() {
return request.auth != null;
}
function isUserAuthenticated(userID) {
return request.auth.uid == userID;
}
match /users/{userID} {
allow read, create, update: if isAuthenticated()
&& isUserAuthenticated(userID)
&& someCondition;
}
}
}
関数定義の活用
Firestoreのルールでは、関数を定義して活用することができます。 共通の処理は関数化することで再利用が出来、記述ミスを減らすことが出来ます。 定義の形としては次のようになります。
function foobar(arg) {
return ...
}
注意点としては、
- 関数は必ず1つのreturn文で構成される
- 変数の定義は行えない
- 必ず何かしらの値をreturnする
となります。 return文で返す値はbooleanに限らずサポートされている型であればなんでも可能です。 また、定義箇所も自由で、状況に応じて配置することが出来ます。
function isAuthenticated() {
return request.auth != null;
}
service cloud.firestore {
match /databases/{database}/documents {
function isUserAuthenticated(userID) {
return request.auth.uid == userID;
}
function getUser(userID) {
return get(/databases/$(database)/documents/users/$(userID));
}
match /users/{userID} {
allow read: if isAuthenticated();
allow write: if isUserAuthenticated(userID);
}
match /articles/{articleID} {
allow read: if true;
allow write: if isUserAuthenticated(request.resource.data.userID)
&& getUser(request.resource.data.userID).data.isActive == true
}
}
}
事前に組み込まれている関数、変数を活用する
事前に準備されているものが多いので、実はルールを構成するのにそんなに困らなかったりします。 特に使うなってのをいくつか挙げておきます。
request, resource
恐らく最も使う変数になるかと思います。前者は動作実行時の状態を表していて、後者はその時のDBの状態を表しています。
なのでrequest.resource と resource では用途が異なってきます。
詳しくはこちらの記事に解説を載せているので合わせてお読みください。


また、request.resource.data、resource.dataはよく使うので、次のような関数を用意すると記述が減らせ楽になります。
function existingData() {
return resource.data;
}
function incomingData() {
return request.resource.data;
}
request.auth
auth認証が通っている前提で組んでいくのであればほぼ使うと思います。また、user的なモデルのdocumentID==auth.uidとして作成するようにしていると色々やりやすいです。
get()、exists()
事前に準備されている関数で、引数にpathを渡してあげると、前者は存在すればそのオブジェクトを返し、後者は存在しているかどうかをbool値で返してくれる
get(/databases/$(database)/documents/users/$(userID))
pathは/databaseから始める必要がある。
$(変数)で変数展開が行える。
返ってくるオブジェクトのfield valueを取りたい場合は、get(...).data.nameのように書く。
in
xxx in yyy のようにして、 xxxがyyy(のmap)に含まれているかみたいなのをチェックするのに使う
match /group/{groupID} {
allow read: if request.auth.uid in request.resource.data.members
}
詳しくはここ見るとどんな関数、変数が提供されているのか分かります。
更新時に特定のkeyの値が変更されていないことを保証したい
例えばcreate時に入れた情報のうち、nameフィールドだけは、その後のupdateで書き換え不可にしたい場合なんかは以下のようにする。
match /users/{userID} {
allow read: if ...;
allow create: if ...;
allow update: if request.auth.uid != userID && request.resource.data.name == resource.data.name;
}
これで、更新はユーザー本人かつ、nameフィールドは作成時のものから変更されていない時のみ許可となる。複数あれば && で繋げていく。
Field ValueがObjectの場合
FirestoreではField valueにObject(json)を持つことが出来ます

この例で言うfoo,barにrules上でアクセスする場合は次のようになります。
request.resource.data.info.foo
request.resource.data.info.foo
特に躓くポイントはなく。ただ、Objectでの == はうまく動かない。
ので中身までチェックしてあげるのが吉。
Field ValueがReferenceの場合
また、Firestoreは他のdocumentへの参照をfield valueとして持つことができます。

rule上では、path型のオブジェクトとして扱われるので、以下のような利用が可能です。
// path型オブジェクトなのでそのままget(),exists()に渡せる
get(request.resource.data.userReference)
exists(request.resource.data.userReference)
request.resource.data.userReference is path // true
また、特定のreferenceと、IDを渡してあげて、参照先が一致するか判定する関数もこんな感じで組めます。
function matchUserReference(ref, userID) {
return ref == /databases/$(database)/documents/users/$(userID);
}
以下は雑多な例ですが、記事を作成、更新する時に、article.userReferenceをセットするのが必須で、
さらにその参照がrequest.auth.uidと一致するuserの参照と一致していたら許可、みたいな感じになっています。
match /article/{articleID} {
allow read: if true;
allow write: if matchUserReference(request.resource.data.userReference, request.auth.uid)
}
ルールの記述のサンプルが見たい
以前に僕が勉強会の登壇で用意したサンプルがあるのでご覧ください。


Advanced
より良いコーディング
インデントや、どこで改行をするべきか、関数やallow式をどこに書くべきか… 迷ったらこちらをご覧ください。

pathを組み立てるときのプラクティス
ルール上でpathを組み立てて、get()関数等で取得するときに、毎回 /databases/$(database)/documents/users/$(userID)のように書いていませんか?
間違えやすいし、長くなりがちなので、次のような関数を用意すると幸せになれます。
function documentPath(paths) {
return path([['databases', database, 'documents'].join('/'), paths.join('/')].join('/'));
}
// /databases/$(database)/documents/posts/$(postID)
allow create: if get(documentPath('posts', request.resource.data.postID)).data.name == '...';


同時書き込みやトランザクションを貼った更新に対するルール
batchを使ったドキュメントの同時書き込みや、トランザクションを貼ってドキュメントを更新する場合のルールを書く場合には、getAfter() 関数が役に立ちます。
例えばcities/{cityID}とcountries/{countryID}を同時にbatchを使ってcreateを行うときに、片方のドキュメントからもう片方のドキュメントを参照したくてget()を使おうとすると、取得することができません。
これはget()関数は、**「現在のDB」からの取得となり、ルールが通って書き込みが行われる前の評価になるので、取得ができません。
これに対してgetAfter()関数は、「今評価しているルールが通ったという前提の基、将来のDB」**から取得になるので、書き込もうとしているドキュメントが取得できます。
以下に詳しくまとめています。

DBの設計とセキュリティールール
ルールを書くにあたってDBの設計の仕方がとても重要になってきます。 現時点では、ドキュメントをクライアント側で取得した場合、ドキュメントのフィールドは全て取得されます。一部のフィールドだけ秘匿して取得することはできません。 なので、秘匿したい情報を保つ場合は、次の2つの方法を取るのが推奨されます。
ドキュメントの下層にサブコレクションを作り、そこに秘匿値を配置する

/users/{userID} ドキュメントがあった場合に、秘匿したい情報があれば、
/users/{userID}/secure/{secureUserID} というサブコレクションとドキュメントを用意します。
そして、次のようにルールを組み立て、ユーザー本人であれば、secureな情報を取得できるようにします。
service cloud.firestore {
match /databases/{database}/documents {
match /users/{userID} {
match /secure/{secureUserID} {
allow read: if request.auth.uid == secureUserID && userID == secureUserID;
}
}
}
}
重要なのは、userIDとsecureUserIDを一致させてドキュメントを作成することです。これにより、secureコレクションからユーザー本人の読み取りかどうかを調べるときに、userIDではなくsecureUserIDを使ってより正確に調べることが出来ます。
そのドキュメントの所属するコレクションとは別のところに秘匿値を置く用のサブコレクションを作り、そこに配置する

こちらの場合は、/users/{userID}とは別に、secureUsers というコレクションを作成し、そこにuserIDと同じドキュメントIDでドキュメントを作成し配置します。
そして、次のようにルールを組み立て、ユーザー本人であれば、secureな情報を取得できるようにします。
service cloud.firestore {
match /databases/{database}/documents {
match /users/{userID} {
allow read: if request.auth.uid == userID;
}
match /secureUsers/{secureUserID} {
allow read: if request.auth.uid == secureUserID
&& exists(documentPath(['users', secureUserID]));
}
function documentPath(paths) {
return path([['databases', database, 'documents'].join('/'), paths.join('/')].join('/'));
}
}
}
こちらの場合はusers コレクション配下に置かないので、管理者側からsecureUsers コレクションの中を走査して何かオペレーションをするときに前者の方法と比べて楽になります。
rules vs Cloud Functions
ルールを書くべきか、ルールを書かずにCloud FunctionsのHTTPsトリガーないしはCallable Functionsでやりとりをするかですが、それぞれPros/Consがあります。
ルールを書いてやりとりする場合
- [Pros] 取得、書き込みといった処理を各クライアントのsdkに一任できる
- [Pros] ドキュメントやコレクションの変更をリッスンしてリアルタイムに情報を取得することができる
- [Pros] ルールでフィールドのバリデーションもかけることができるので、不正な値を書き込まれることを事前に防ぐことができる
- [Cons] ルールが間違っている場合の原因の特定が慣れないと難しい(permission-deniedとしか表示されない)
- [Cons] 読み書きの処理は各プラットフォームで記述しないといけないので、頑張って統一する必要がある
- [Cons] 誤ったルールを記述してしまうとセキュリティリスクになる
Cloud FunctionsのHTTPsトリガーを使う場合
- [Pros] ルールを開けないのでセキュリティは強固になる
- [Pros] 関数内ではadmin権限でDBを操作することができるので、ルールの影響を受けることなくやりたいことが実現できる
- [Pros] APIを定義するような形になるので、複数のプラットフォームで行う処理を統一することができる
- [Cons] トリガーの入り口をしっかり守る必要が出てくる(認証情報、token,Callable Functionsの検討…etc)
- [Cons] 関数の実行が遅い場合がある
個人的には、セキュリティー的にどうしても守らないといけないもの、Firebaseの外とのやりとりが発生するもの、トランザクション等処理が複雑化してしまうようなものに関してはルールを記述せず閉じた状態にして、Cloud Functionsを活用するようにしています。
それ以外に関しては、適切なルールを敷いた上で、クライアント側に提供されているSDKを介して読み書きを行うようにしています。その方が簡単であり、リッスンして変更を受け取るのも容易なので。
テストを書く
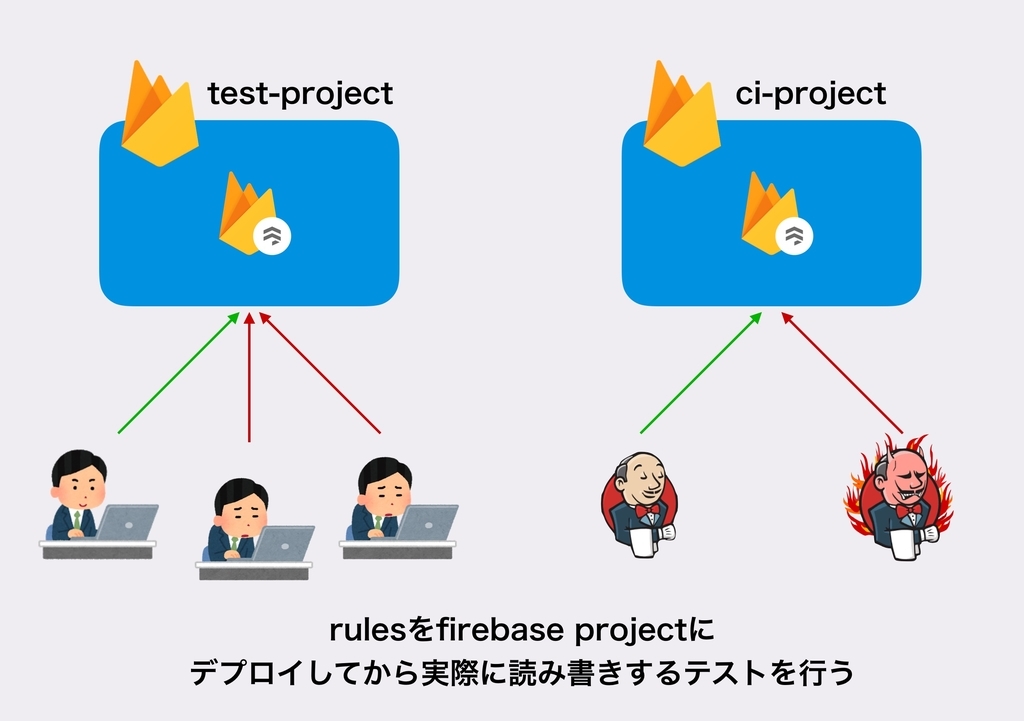
実際に書いたルールが期待通りに動くか、テストを書いて確かめましょう。 テストを書くことで、ルールの変更によってルールが壊れてしまうのを防ぐことができますし、事前に想定しうるパターンをテストしてルールが妥当なものか判断することができます。 テストの手法としては、主に2つあります。
- 実際にFirebaseのプロジェクトのDBに書き込む方法
- ローカルエミュレータを使う方法
以前までは、前者の方法でしかテストを書くことができなかったのですが、2018年に行われたFirebase Summitの発表後から、ローカルエミュレータがFirebaseから提供され、これを用いてテストを書くことができるようになりました。
テストの導入や書き方に関してはいずれも以前に書いた記事がありますのでご覧ください



その他
ruleはgit管理+CLI経由でデプロイする
毎回webのコンソールで書いて更新..だと非効率だし手元で変更管理ができないので、firestore.rulesファイルをgit管理し、CLIでデプロイするようにします。
また、前述のローカルエミュレータを使ったテストを書く際は手元でガンガンfirestore.rulesファイルを書き換えることになるので、git管理するようにしましょう。
セットアップ
まだ手元でセットアップしていなければ
$ firebase init firestore
を行い、指示に従ってセットアップすると firestore.rulesが生成されます。(内容は直近のconsoleの内容が入ってくるはず)
デプロイ
ルールのみデプロイする場合は
$ firebase deploy --only firestore:rules
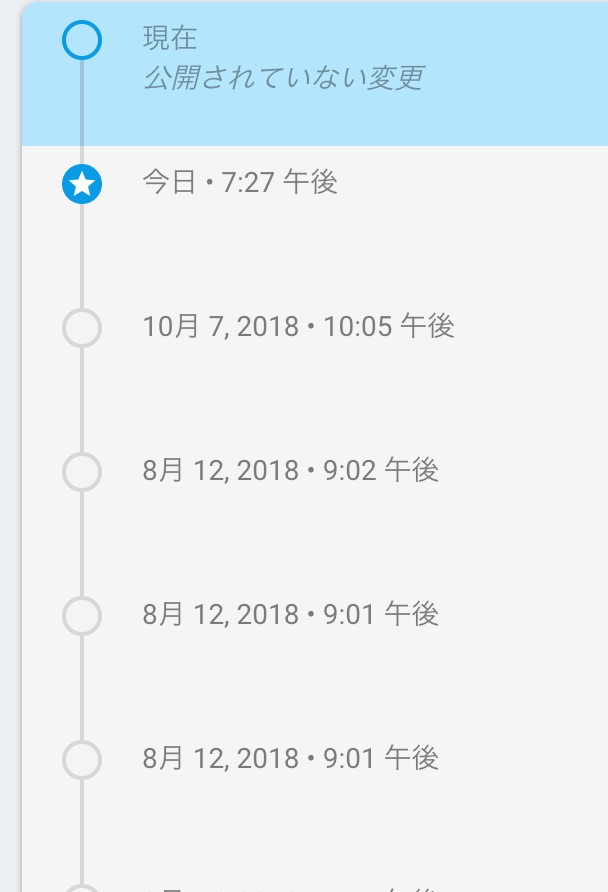
でいけます。反映には最大で1分ほどかかることがあります。 デプロイ後は、webのコンソール上でデプロイした履歴と、変更のdiffを確認することができます。
ルール書くのにおすすめのプラグイン
VSCodeを使っているならtoba/vsfireがおすすめです。 rulesを書く時に syntaxが効いてくれるので書きやすくなります。ある程度の予約語(?)ならauto-completionもかかります。

Learn more about rules…
拙著にはなりますが、いくつか記事を書いているので併せてお読みください。